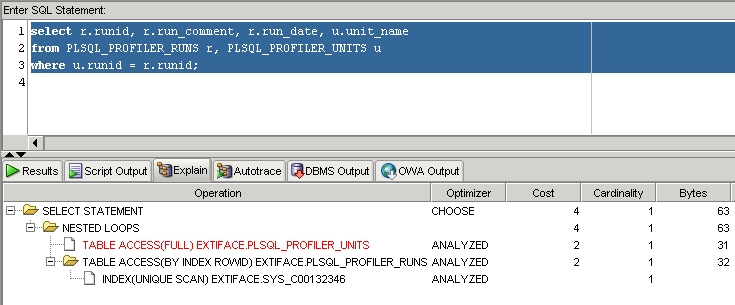
While doing an information hunt, I came across the NYOUG presentations here which includes the pdf of a Tom Kyte presentation on 11g PL/SQL enhancements.
If there is a policy of not releasing these presentations, there's a chance Oracle will ask for it to be removed from the site so best "get it while its hot".
May ratings are :
- DML in triggers is faster - 2. We are putting that code into packages anyway, aren't we ?
- Fine Grained Dependency Tracking - 8. Very useful for impact analysis.
- Native compilation - ?. Depends on whether there is a significant performance benefit.
- Intra-unit inlining -5. Anything that allows use to write more readable code with no performance hit is bound to be good.
- Function result cache - 7. Looks good, but we'll have to watch that RELIES clause
- SQL result cache - ?. If it is a straight query with no variables, isn't it a materialized view ? Wonder how it works with variables and/or SYS_CONTEXT
- Compound trigger -?. Sounds good, but I can see people trying to put validation in there that doesn't cater for concurrent table updates.
- Dynamic SQL -3. I don't see much use of it, but anything that makes it more practical to keep the SQL in the database and away from those Java developers must be good :)
- Fine-grained access control for UTL_FILE/UTL_HTTP/... - 8. More security GOOD.
- Regular expression enhancements-?. Not something I've used.
- Super-?. Also not something I'm familiar with.
- Read only table-2. Check out the Dizwell article on this. Is it really Read Only (and could we apply it to individual partitions ?)
- Disabled trigger-1. Don't we test these things ?
- Trigger firing order-1. Do we need to make triggers MORE complicated ?
- "When others without raise" warning-7.
- Direct use of sequence.nextval in PL/SQL-7.
- "Continue" command for loops-2. Spaghetti code.
- Named parameter referencing for functions called from SQL-7. Readability improvement.